4D Interactive Viewer














Demo








Overview Video
Abstract

We present Free4D, a novel tuning-free framework for 4D scene generation from a single image. Existing methods either focus on object-level generation, making scene-level generation infeasible, or rely on large-scale multi-view video datasets for expensive training, with limited generalization ability due to the scarcity of 4D scene data. In contrast, our key insight is to distill pre-trained foundation models for consistent 4D scene representation, which offers promising advantages such as efficiency and generalizability. 1) To achieve this, we first animate the input image using image-to-video diffusion models followed by 4D geometric structure initialization. 2) To turn this coarse structure into spatial-temporal consistent multiview videos, we design an adaptive guidance mechanism with a point-guided denoising strategy for spatial consistency and a novel latent replacement strategy for temporal coherence. 3) To lift these generated observations into consistent 4D representation, we propose a modulation-based refinement to mitigate inconsistencies while fully leveraging the generated information. The resulting 4D representation enables real-time, controllable spatial-temporal rendering, marking a significant advancement in single-image-based 4D scene generation.
Method
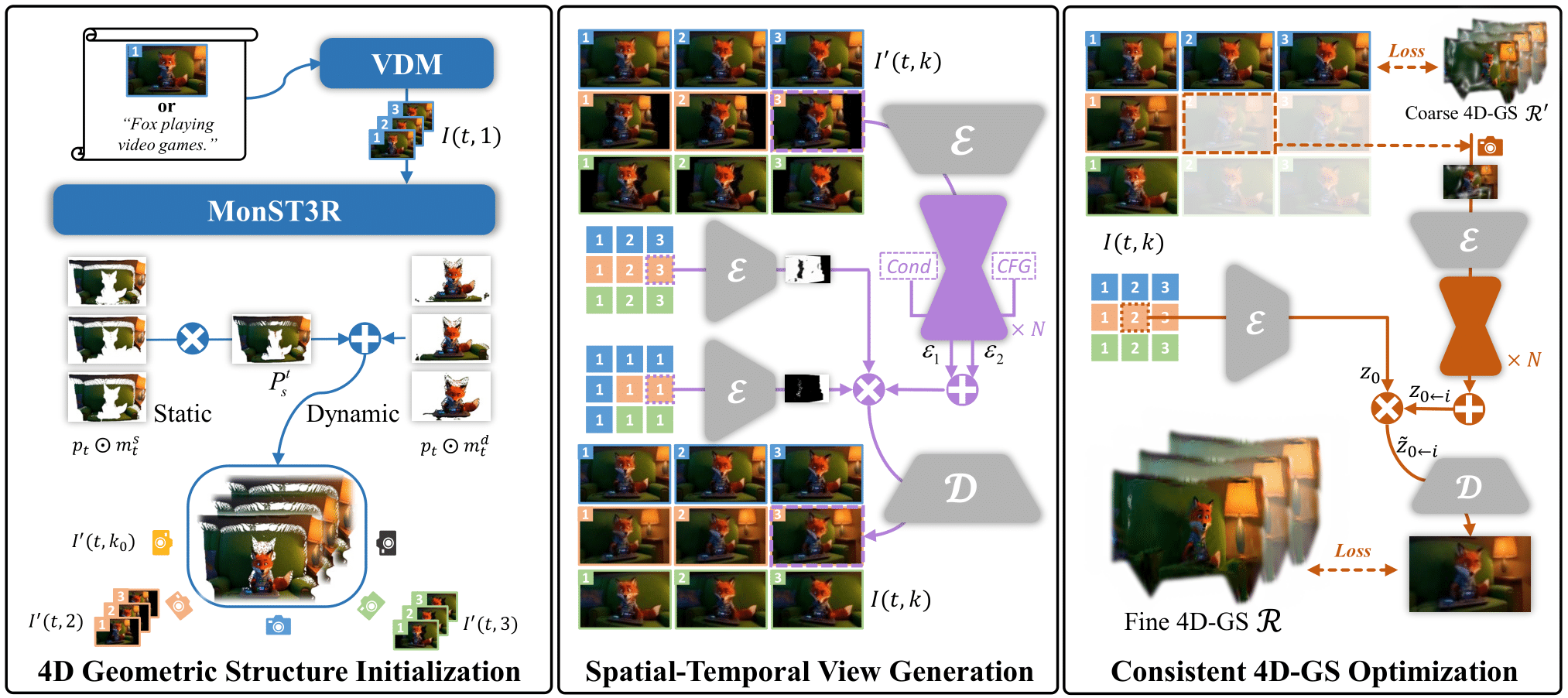
- Given an input image or text prompt, we first generate a dynamic video \( \mathcal{V} = \{I(t,1)\}_{t=1}^{T} \) using an off-the-shelf video generation model.
- Then, we employ MonST3R with a progressive static point cloud aggregation strategy for dynamic reconstruction, obtaining a 4D geometric structure.
- Next, guided by this structure, we render a coarse multi-view video \( \mathcal{S}^{\prime} = \{\{I^{\prime}(t,k)\}_{t=1}^{T}\}_{k=1}^{K} \) along a predefined camera trajectory and refine it into \( \mathcal{S} = \{\{I(t,k)\}_{t=1}^{T}\}_{k=1}^{K} \) using ViewCrafter. To ensure spatial-temporal consistency, we introduce Adaptive Classifier-Free Guidance (CFG) and Point Cloud Guided Denoising for spatial coherence, along with Reference Latent Replacement for temporal coherence.
- Finally, we propose an efficient training strategy with a Modulation-Based Refinement to lift the generated multi-view video \( \mathcal{S} \) into a consistent 4D representation \( \mathcal{R} \).
Text-to-4D Comparisons
4Real (Left) vs. Ours (Right)
"A baby rabbit is eating ice-cream." "A goat drinking beer." "A monkey eating a candy bar."
Dream-in-4D (Left) vs. Ours (Right)
"A rabbit eating carrot." "A baby rabbit is eating ice-cream." "A monster reading a book."
4Dfy (Left) vs. Ours (Right)
"A monkey eating a candy bar." "A baby rabbit is eating ice-cream." "A baby panda reading a book."
Image-to-4D Comparisons
GenXD* (Left) vs. Ours (Right)
* denotes the video rendered by 4DGS, which is trained using the videos sourced from GenXD's project page.

DimensionX (Left) vs. Ours (Right)


Animate124 (Left) vs. Ours (Right)


More Results



Citation
@InProceedings{Liu_2025_ICCV,
author = {Liu, Tianqi and Huang, Zihao and Chen, Zhaoxi and Wang, Guangcong and Hu, Shoukang and Shen, Liao and Sun, Huiqiang and Cao, Zhiguo and Li, Wei and Liu, Ziwei},
title = {Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {25571-25582}
}
Related Works
-
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
-
Dream-in-4D: A Unified Approach for Text- and Image-guided 4D Scene Generation
-
4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
-
GenXD: Generating Any 3D and 4D Scenes
-
DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion
-
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
-
DreamGaussian4D: Generative 4D Gaussian Splatting
-
L4GM: Large 4D Gaussian Reconstruction Model